The probability of software defects is difficult to estimate. It’s so difficult that the “old” DIN EN IEC 62304:2006 wrote: “However, there is no agreement on how to determine the probability of the occurrence of software failures using traditional statistical methods.”
The standard concluded that “the probability of such a malfunction must be assumed to be 100 percent”. The “new” IEC 62304:2015 has deleted this highly problematic requirement.
This article describes how you can realistically estimate the probability of software defects and when to do this.
1. Probability of defects for IEC 62304
a) Problems of the “old” DIN EN IEC 62304:2006
DIN EN IEC 62304:2006 (Medical Device Software – Software Life Cycle Processes) requires: The probability of a software defect that could lead to a hazard must be assumed to be 100%.
“If the HAZARD could result from the SOFTWARE SYSTEM not behaving in accordance with its specification, the probability of such a malfunction shall be assumed to be 100%.”
IEC 62304:2006
The authors actually wanted to express this: One should not argue with the probability of software defects.
“Working in ISO/IEC JWG3 I followed these discussions and want to point out, that this 100% assumption is used for the safety classification only – and it is NOT used for reasoning about ACCEPTABLE or ALARP in some Risk Analysis.”
Georg Heidenreich (NAMed, DIN Standards Committee for Medicine)
One major problem with this is obvious: If you assume a probability of defects of 100% for standalone software, then the probability of damage is very high, and the associated risk is rarely acceptable (Fig. 1):
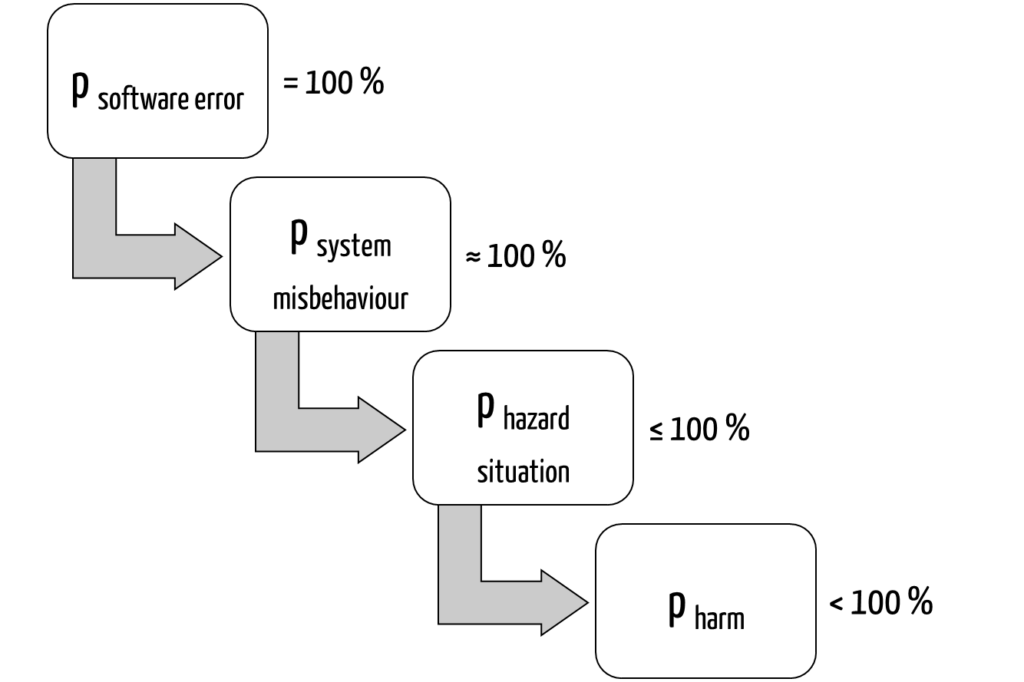
A software defect (assumed here with 100% probability) could lead to damage as follows:
- The software works incorrectly: it almost always (in approx. 100% of cases) displays an incorrect medication.
- The probability that this leads to a hazardous situation (e.g., taking the wrong medication) depends on how likely the defect will be detected. This probability is less than 100%.
- The probability that damage of a certain severity (e.g., anaphylactic shock) will occur as a result – and thus the level of risk (!) – depends on how well the patient tolerates the incorrect dose. It should definitely be less than 100%.
Depending on the context, the probability of damage is between 1% and less than 100%. As a rule, however, the associated risk is probably unacceptable.
So, you can’t reasonably act with a 100% probability in such cases. Instead, you want to estimate the actual probability of software defects and determine the risk based from this.
b) The “new” IEC 62304:2015 deletes the fatal passage
The good news here is: Amendment I of the “new” IEC 62304:2015 has removed the stumbling block (Fig. 2).

Instead, the standard now states: “There is no known method to guarantee 100% SAFETY for any kind of software.” This trivial statement can be agreed with in the cases relevant to medical device manufacturers. (Note: The use of the term safety in this context could be reconsidered in the next version of the standard).
The “new” IEC 62304 still states: “Probability of a software failure shall be assumed to be 1”. However, the standard makes it clear that it only means this for a very specific context: “In determining the software safety classification of the software system.”
IEC 62304:2015, therefore, does not say that a 100% probability of defects must always be assumed for software. For risk estimations, for example, you may operate with more realistic probabilities of defects.
2. Definition of the probability of software defects
In the case of defects, a distinction must be made between defects (states) and defect effects. They are defined as follows:
Faulty program part, instruction, or data definition that is causally responsible for a defect effect
ISTQB Glossary
The effect of a defect that occurs during the execution of the program under test and is visible to the user.
ISTQB Glossary
Not every defect (state) leads to a defect effect. For example, calling a method on an uninitialized object does not lead to a defect effect if this code is never run or if defect handling catches and neutralizes this defect.
In this article, we understand “defect probability” as the probability of a defect occurring.
With the help of templates and videos, you will learn how to create a complete risk management file with all the necessary documents. Check your documents for legal compliance and avoid errors during audits and submissions.
3. Estimating the probability of software defects
Setting a maximum probability as a target value is one thing. Finding out whether you have reached it is another.
a) Literature data
Literature values can help to estimate probabilities of defects:
- 1.4 critical and 23 non-critical defects were found per 1000 lines of a safety-critical system.
- For commercial software such as Windows XP, it is assumed that there are 30 defects per 1000 lines, corresponding to more than 1 million defects for 35 million lines. Nevertheless, Windows XP has an MTBF (mean time between failures) of 300 hours.
- It is assumed that there are 10E-7 software defects per hour for cars and airplanes. (These figures do not contradict the requirements for the probability of defects of means of transportation).
The problem remains: Although this data helps estimate probabilities of defects, it does not constitute proof that these are achieved.
b) Trial and error
The actual probability of encountering defects (state) can only be determined in practice or by trial and error. There are two approaches to this:
- Testing
- Observe in productive use
1. Testing
Testing helps to estimate at least an upper limit to the probability of defects. Of course, the code must be run through during testing. The most complete test coverage possible is a necessary prerequisite for deriving reliable figures (MTBF, probability of defects, defects per 1000 lines of code (kLoC)).
The code mutation provides further information on how sensitively the selected test cases detect defects.
In any case, all usage scenarios should be tested.
The test duration is not a meaningful measure of quality or completeness, especially for automated tests (as claimed elsewhere).
2. Productive use
The “most representative test cases” and therefore the most reliable figures can be obtained from the field. Use this:
- Feedback from users
- Your own observations
- Evaluations of defects and audit logs
- Surveys of users
- Evaluation of the data entered
Usage statistics help you to review whether your tests cover all actual usage scenarios.
However, this data is generally unavailable when a new device is approved.
If this data is missing, then take note:
- Comparable predecessor products provide you with pretty good reference points.
- Use the FDA and BfArM defect databases.
- Tests help you to estimate an upper limit of probabilities.
d) Modeling and calculation
Mathematical models such as Markov chains help to calculate the probabilities with which defects are multiplied. These probabilities can often not be calculated as the product of the individual probabilities.
Annex D of IEC 61508-3 provides an overview and brief introduction, particularly in Subchapters D.3 to D.7.
In practice, however, these procedures are rarely used for software (!). The reasons for this are
- their complexity,
- the difficulty of transferring them to software, and
- the lack of mapping of the software to a model.
e) Code coverage data
Some papers examine the relationship between code coverage and defect detection.
Gopinath et al. note in their evaluation of hundreds of open source projects that (contrary to some scientific studies) statement coverage provides the best quality prediction compared to branch coverage or path coverage. This was shown not only by manually built tests but also by automatically generated tests.
The following figure is taken from the linked publication. It shows the relationship between statement coverage and mutations found.
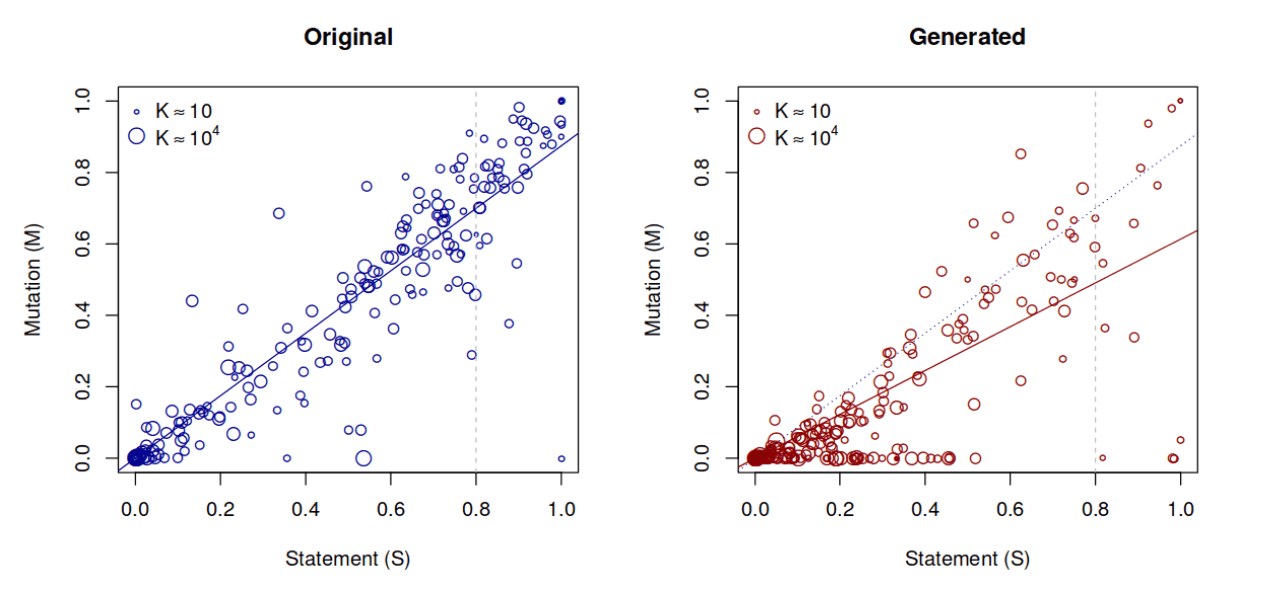
The question “Is there a correlation between the quality of the test and the probability of a particular software problem?” can be answered clearly with a yes:
For example, in a project comparable to the examples studied, you can expect to find about 70% of defects with a statement coverage of 80%.
However, you can see from the plot on the right that this metric should not be considered alone but that the nature of the tests is also relevant: Manually built tests seem to find defects more reliably than automatically generated ones. It is also interesting to note that the size of the test suite had no effect.
It should be noted that these are exclusively Java projects. However, it can be assumed that this correlation can be generalized to other languages.
f) Conclusion
Estimating the probability is difficult. So what?
The probability of software defects is indeed very difficult to estimate. However, you can do more than just estimate the order of magnitude based on literature data and your own measurements.
Other probabilities are also difficult to estimate, such as those of use errors. However, nobody would think of demanding a worst-case assumption of 100%, as IEC 62304 did. At least, that is how the “old” standard could or had to be (mis)understood.
If you develop your software according to the rules of the art (as presented in IEC 62304, and even more so in IEC 61508-3) and test the software with code coverage (at least of the relevant parts) close to 100%, you should be able to assume a probability of defects of your software of ≤ 10-2 per use case, even if the software has been newly developed. The probabilities of defects of productive and proven software should be at least an order of magnitude smaller.
4. Necessary probability of defects for software
There are several variants for estimating the maximum probability with which a software may have a (critical) defect effect.
a) Apply product-specific risk acceptance criteria
The probability of a software defect can be derived from the risk acceptance matrix: To do this, you start with an assumed damage, read its maximum probability from the acceptance matrix and trace the chain of causes backwards to the software defect (FTA approach).
In other words, you follow the steps shown in Fig. 1 in reverse order and deduce the maximum probability of a software defect from the maximum probability of a damage.
b) Apply other acceptance criteria
Some industries require very low probabilities of defects, such as 10-9 per operating hour (civil aviation) or 10-12 per operating hour (railroads). However, this does not mean that the software can or must achieve this level of quality. Manufacturers usually only achieve the required low probabilities of defects by implementing risk-minimizing measures in the hardware (e.g., redundancy).
5. Reducing the probability of software defects
The most effective way to develop software with few defects is to avoid defects consistently – and not (only) try to find these defects during testing and then eliminate them. That is why IEC 61508-3 focuses precisely on this: it specifies the measures manufacturers must take to achieve a defined safety level.
Read more about the aspects of design quality assurance here.
Ultimately, manufacturers must minimize the likelihood of damage. Reducing the probability of software defects is only one possibility. IEC 62304 even requires risk-minimizing measures outside the software in order to be allowed to reduce the software safety class.
6. Argumentation aids
Some auditors and “technical file reviewers” still cling to the sentence in the (old) IEC 62304, which sets the probability of defects at 100%. The following considerations may help you in your argumentation:
- That the probability of defects is 100% is refuted by the fact that you perform a test that leads to the specified outputs. The assumption in the “old” IEC 62304 is thus refuted.
- The “old” IEC 62304 no longer represents the state of the art. This is (more likely) represented by IEC 62304:2015.
- The unspeakable 100% statement was already made in the old standard in the context of safety classification. The point was that probabilities were not discussed in this classification. This is exactly what the new IEC 62304 makes clear, and that makes sense.
- ISO 14971 allows and even requires probabilities to be determined. There is no other way to quantify and assess risks.
- As the probability classes of the risk acceptance matrix usually cover two orders of magnitude, it is not necessary to estimate the probability of software defects to within 10%.
- IEC 61508-3, probably the most important standard for safety-critical systems, prescribes how to develop software professionally. And you have (hopefully) based your “safety level” on this.
7. Conclusion
The best protection against software defects is constructive quality assurance and measures implemented outside the software system. You should primarily strive for both.
However, the “external measures” approach does not work for standalone software. But here, too, you can at least estimate the magnitude of probabilities of defects.
This article has outlined how this estimation can be successful and how you can determine and achieve target values.
The Johner Institute supports medical device manufacturers in creating FDA and IEC 62304 compliant software files.
Get in touch to find out how the team can help you quickly develop your devices and guide them safely through approvals and audits by providing templates and reviewing, improving, and creating documents.
Change history
- 2023-04-03: Article updated and many editorial changes added
- 2020-06-10: First version of the article