Is there a duty for medical device manufacturers for validating ChatGPT and other LLMs that they use in the development, production, approval, and monitoring of their products?
If so, how can this be achieved with models that deliver non-deterministic results?
This technical article provides answers to these questions and to the question of what your auditors (should) expect.
- Medical device and IVD manufacturers must be prepared for their auditors to address the validation of GPTs.
- In many cases, there is a regulatory obligation to validate tools such as ChatGPT. This is particularly the case when they are used in processes within the QM system.
- This validation is possible, but differs in some respects from the validation of conventional computerized systems.
- Manufacturers should limit the effort required for GPT validation based on risk.
- Not using GPTs or LLMs due to CSV requirements jeopardizes competitiveness.
1. Use of GPTs by medical device manufacturers
Medical device and IVD manufacturers are increasingly turning to GPTs to improve their productivity, innovation, and sometimes even compliance.
- Brainstorming for new product ideas
- Checking intended use for completeness and consistency
- Extracting requirements from documents (e.g., laws, product descriptions)
- Creating a system architecture
- Writing source code
- Researching and evaluating clinical literature
- Evaluating customer feedback
- Compiling test reports
Some of these activities are only performed once or rarely by employees. Others, such as evaluating customer feedback, are performed on a regular basis.
2. Regulatory requirements for validating ChatGPT
To avoid problems during audits and inspections, manufacturers should be familiar with and comply with regulatory requirements.
2.1 AI Act
The use of LLMs and GPTs falls within the scope of the AI Act. This is because MP manufacturers who use LLMs/GPTs internally in this way are considered “deployers” of these systems, even if they do not operate them themselves.
As a rule, these systems are not considered high-risk, which is why there are no further requirements apart from the obligation to demonstrate AI literacy. In particular, the AI Act does not require validation.
Please refer to the technical articles on the AI Act and the additional obligations of medical device and IVD manufacturers as deployers. Another article highlights the regulatory requirements for medical devices and IVDs that use machine learning methods.
2.2 ISO 13485
ISO 13485 also requires proof of competence, even specifically for each development project. However, this is not the focus of this article; the primary focus here is on the obligation to validate.
In Chapter 4.1.6, ISO 13485 requires the validation of all computerized systems used within the QM system. This is the case, for example, in all of the above-mentioned use cases.
ISO 13485 imposes similar, and in some cases even identical, requirements on infrastructure (section 6.3) and on the validation of processes, including the software used in them (section 7.5.6).
2.3 Additional regulatory requirements
The FDA formulates similar requirements in its Quality System Regulations (21 CFR part 820). However, the authority is converting its system to the Quality System Management Regulations and thus to ISO 13485.
Please refer to the technical articles on the Quality System Management Regulations (QMSR).
In Korea and other countries, compliance with the ISO 42001 standard, which also addresses the quality assurance of AI-based systems, is mandatory.
Please refer to the technical article on ISO 42001 and its requirements.
3. LLMs as computerized systems
Are LLM-based GPTs computerized systems within the meaning of ISO 13485?
The short answer is yes.
The more detailed answer is that LLM-based systems count as computerized systems. If manufacturers use these systems as part of one or more QM processes, these systems are subject to the requirements of ISO 13485.
“The organization shall document procedures for the validation of the application of computer software used in the quality management system.”
However, it is not the LLMs, i.e., the models themselves, that need to be validated, but rather the computerized system. This consists of more than “just” the LLM (see Fig. 1), which usually comes from one of the major provider such as OpenAI (ChatGPT), Google (Gemini, SORA), Microsoft (Copilot), or Anthropic (Claude).
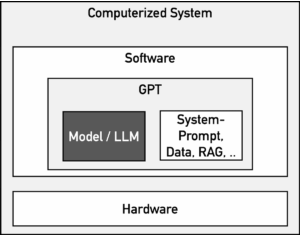
It is irrelevant whether a system is operated by the provider (e.g., OpenAI) or by the medical device or IVD manufacturer itself. The decisive factor is that the manufacturer uses it under its QM umbrella.
4. Validation requirement for GPTs
Manufacturers must validate their AI, e.g., their ChatGPT, if the conditions listed in Fig. 2 are met. The following subchapters explain the individual steps.
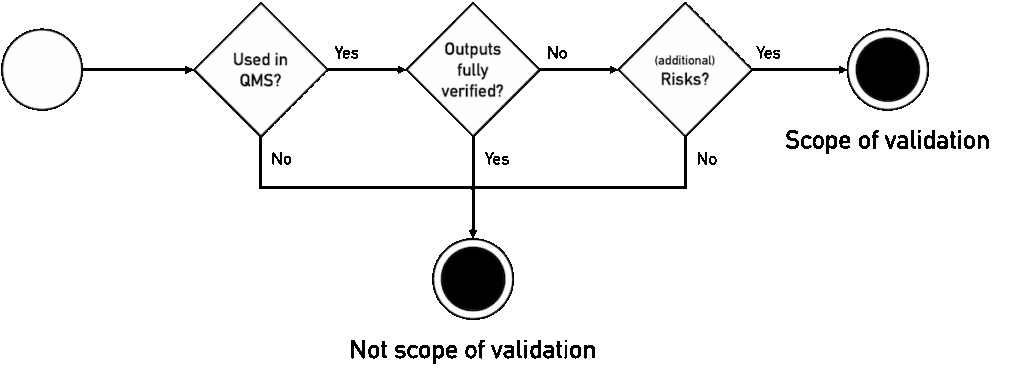
4.1 Decision criteria
4.1.1 Yes, if within the scope of the QM system
ISO 13485 requires organizations to describe the processes within the scope of their QM system in section 4.1.2. These are at least the processes specified by the standard itself, for example:
- Development, including verification and validation of products
- Collection of regulatory and customer-related requirements
- Production
- Service provision
- Post-market surveillance
- Handling customer feedback
- Communication with authorities, including vigilance
All activities mentioned in Section 1 and supported by LLMs fall within the scope of the company’s own QM system!
LLMs used in outsourced processes are subject to the same regulatory requirements and therefore also to the obligation to validate them.
4.1.2 No, if the results are fully verified
ISO 13485 does not describe any exception to the validation requirement for computerized systems in section 4.1.6. Nevertheless, such an exception can be derived if the results of the computerized system are subsequently fully verified.
This argument is based on the following considerations:
- The manufacturer does not have to meet the very similar requirements for tool or process validation if the following applies: “output [is] verified by subsequent monitoring or measurement and, as a consequence, deficiencies become apparent.”
- The FDA expresses the same view in 21 CFR part 820.75 a).
- The permission to take a risk-based approach means that if there is no risk, no validation is necessary.
Subsequent monitoring or measurement can be carried out by
- a manual check,
- automated tests (e.g., software), or
- subsequent process steps that inevitably reveal faulty outputs from the GPT (e.g., because a component cannot be assembled).
4.1.3 No, if no (additional) risks arise from faulty outputs of the LLM
Following the above consideration, manufacturers do not need to validate their LLM if there is no (additional) risk. In this context, the word “risk” refers to two different types of risks:
- Risks to patients, users, and third parties within the meaning of ISO 14971 (strictly speaking, the standard also considers the environment and goods)
- Risks to the conformity of the company itself and its products
An interesting technical article by Dr. Sebastian Raschka describes how LLMs can be validated.
4.2 Examples
4.2.1 Examples of GPT-based systems not subject to validation
| Example | Reason |
| Brainstorming product ideas | It is irrelevant whether ideas come from humans or LLMs. In either case, humans will review these ideas and either reject them or continue to use them. |
| UI design | A UI design cannot usually be adopted automatically. In practice, therefore, humans will evaluate and adapt this design before it is implemented and assessed as part of formative and summative evaluation. Here, too, it is irrelevant whether the initial UI designs originate from humans or LLMs. |
| Generating software code (but not test code) | Software code is never error-free. That is precisely why it should be checked particularly thoroughly, e.g., by the compiler, reviews, software tests, static code analyses, and subsequent testing steps such as integration tests. If LLM-generated code is subjected to precisely these quality assurance measures, the risks are minimized to the same extent as for code written by humans. This applies in particular to boilerplate code. Manufacturers do not usually allow code for critical algorithms to be generated. Otherwise, validation of the GPT would be recommended. |
| Generating SOPs | SOPs must be reviewed and approved. This also applies to generated SOPs. Thus, the end result is fully verified by humans. |
The examples in Table 1 assume that humans actually perform their task and check the results. This is more often the case with GPTs that are used infrequently than with GPTs in routine operation. Developers who are used to their GPT generally high-quality code tend to be less inclined to check this code carefully.
Manufacturers can counteract this automated approval (“automation bias”) by, for example, raising awareness of the issue in AI literacy training courses and demanding concrete review results.
4.2.2 Examples of borderline cases
| Example | Reason |
| Writing a software architecture (analogous to system architecture, isolation diagram, power supply concept) | Design documents undergo many other explicit and implicit review steps: Document reviews take place. The development team implicitly reads and reviews the document during implementation (e.g., for completeness, correctness, feasibility). The development results go through many other test steps. This does not mean that an error caused by the LLM will always be detected and risks excluded, but the risks should be lower with a good/proven prompt than with a manually created design document. The quality of the prompt (or the prompt chain or the complete GPT) could be ensured through reviews. Conclusion: There must be good reason for not validating the GPT. |
| Writing test code | Test code is almost never tested for correctness and completeness by further software tests. However, the test code is also checked by the compiler, it (ideally) undergoes a code review, and it is at least indirectly checked by coverage determination. Thus, the validation requirement depends on the type and intensity of subsequent test steps as well as on the criticality of the tested software. |
4.2.3 Examples of GPT-based systems subject to validation
| Example | Reason |
| Writing a test plan | Errors in test plans can take the form of incorrect limit values or missing test criteria or test cases, for example. Such errors are more difficult to find than in design documents, as a gap in the test plan leads to an insufficiently tested test object (e.g., product). On the other hand, there is a higher risk that the search for these errors (e.g., during reviews) will be compromised by time pressure at the end of the project and declining motivation. The nature of LLMs can lead to errors that humans would not make. In this respect, an argument based on the state of the art (human) does not apply. |
| Determining regulatory requirements | ly determining regulatory requirements is crucial for the conformity of the product or company. Therefore, errors lead to significant (regulatory) risks. Unlike GPTs, humans do not tend to invent, completely falsify, or ignore regulatory requirements. This increases the risks of LLMs relative to the risks of manual determination. |
| Evaluating clinical literature | Similar considerations apply to LLMs that search for, scan, or evaluate clinical literature. Clinical evaluations using literature sources invented by LLMs have already found their way to notified bodies. Such unvalidated LLMs undermine the usefulness and relevance of clinical evaluation. |
| Evaluating customer feedback | Errors in the evaluation of customer feedback would result in critical feedback going undetected and the necessary measures not being taken. This can endanger patients. |
4.3. Conclusion
Manufacturers should consider several criteria when deciding on the need for validation. In addition to those mentioned in section 4.1, these include the following:
4.3.1 Subsequent process steps
The less capable subsequent process steps are of detecting possible errors in a previous step, the more important the quality of the previous process step becomes. Manufacturers should therefore validate tools such as ChatGPT more thoroughly when they are used on the right-hand side of the V-model.
4.3.2 Frequency and type of use
Validation also appears to be particularly necessary when a tool such as a GPT is used routinely, for example to evaluate customer feedback.
On the other hand, a person who develops a special tool for a one-time use to solve a specific problem is highly likely to thoroughly check the results of that tool.
5. GPT validation practice
5.1 Observe general CSV best practices
Legal and normative requirements such as ISO 13485 do not distinguish between whether a computerized system uses LLMs or not. Therefore, all CSV best practices are also applicable to GPTs.
Please refer to our technical article on Computerized Systems Validation . This article references additional guidelines and standards such as IEC 80002-2.
5.2 Implement specific risk management
However, the validation of AI-based computerized systems, especially systems that use generative AI, differs from the validation of systems that do not use AI. Among other things, this applies to risk management, which is particularly relevant in validation due to the risk-based approach .
5.2.1 Specific risks
AI-based systems have specific risks that can have various causes:
- The technologies and models are subject to constant change.
- The results are rarely 100% correct and complete.
- GPTs make mistakes that humans would not make.
- LLMs (the models at the core of GPTs) are difficult to validate.
- Many GPTs can also be used for purposes for which they were not intended or validated.
The risks depend heavily on the inputs and their variability. For example, the risks of a GPT that accepts any prompt are more difficult to assess than those of a GPT that only accepts structured data in a specified format and with defined semantics (e.g., values from classification only).
This article does not address AI-based medical devices and IVDs. Please refer to our overview article and the article on regulatory requirements for machine learning.
5.2.2 Specific risk mitigation measures
The measures also differ:
- Human-in-the-loop
- System architecture (e.g., parallelization with subsequent voting by multiple LLMs or limiting the LLM to the role of “conversational UI”)
- Evaluation of the “protocols” (as required by the AI Act for high-risk systems)
- Selection of model parameters, such as temperature and top-K (e.g., to increase reproducibility)
- Use of structured data in the context window
5.2.3 Specific criteria for risk acceptance
Preliminary remark
German legislators, authorities, and notified bodies in particular tend to believe that more bans and stricter interpretation of legal requirements lead to increased patient safety. However, this attitude in turn provokes risks due to a lack of affordable and sufficiently innovative/effective medical devices.
Manufacturers should therefore also be able to argue the benefits of AI in their risk assessments. Without benefits, no risks are acceptable.
State of the art
In addition, a company should not assess risks in absolute terms, but rather measure them against the state of the art. The state of the art is defined by:
- People
- Systems without AI
- AI-based systems that use AI differently (other models, architectures, etc.)
The state of the art in evaluating clinical literature is humans, specifically medical and scientific experts.
The state of the art in the statistical evaluation of production errors or customer feedback is classic software applications (without AI).
Therefore, errors that would not occur with the current state of the art (e.g., invented legal texts or scientific sources) but do occur with chatbots are unacceptable.
On the other hand, an overlooked customer complaint or incorrectly classified customer feedback is not a criterion for excluding the use of an LLM. After all, humans also make such errors.
Manufacturers should also derive the requirements (e.g., in the form of quality metrics) from the state of the art and thus on a risk-based basis – and check them.
5.3 Observe other specific best practices
5.3.1 Define what the GPT is
Manufacturers must be clear about what the system to be validated is and what the input to that system is. For example, a prompt can be an input, but in the case of custom GPTs or system prompts, it can also be part of the system to be validated.
As described in section 5.2.1, the risks depend heavily on the inputs and their “variability.”
5.3.2 Determine ground truth
A manufacturer should be clear about which results are correct. In many cases, this is more difficult than expected.
The Johner Institute has found that different experts do not fully agree on which sentences or sentence fragments in regulatory documents formulate requirements and which “only” serve as explanations, justifications, or examples.
Similarly, even individuals classify customer feedback differently when presented with it multiple times.
The question of which element in a chain of causes is a hazard, a hazard class (e.g., electrical energy), a cause of hazard, or a “root cause” also leads to reproducibly different answers.
It is therefore essential that a sufficient number of data sets are available.
- which are provided to the LLM as examples (→ n-shot prompting) and
- which can be used to evaluate the performance of the GPT.
When using a GPT to evaluate customer feedback, it is helpful to “label” several hundred customer feedback responses. To do this, data sets would have to be evaluated by multiple people as well as multiple times by one person.
This allows manufacturers to
- determine intrapersonal and interpersonal variance (and derive metrics from this) and
- compile examples of clearly critical and clearly non-critical customer feedback as well as controversial feedback.
5.3.3 Determining metrics
Only when these examples are available does it make sense to determine the quality metrics. The choice of these metrics depends heavily on the purpose of the GPT.
For a GPT that identifies security-related information in customer feedback, accuracy (percentage of correctly classified customer feedback) is not the appropriate measure. Sensitivity is a more suitable measure in this case.
5.3.4 Do not limit validation to metrics
Depending on the task, manufacturers should not limit their testing to compliance with metrics. This would only allow them to check “the mean value.” Therefore, other metrics and investigations are recommended:
- Determination of the “confidence interval” for each metric
- Investigating how strongly the performance of individual “features” depends on other factors. “Partial dependency plots” or “feature importance plots” can be helpful here.
- Manufacturers should also consider the classic software quality characteristics according to ISO 25010, such as robustness, performance, and IT security.
For a GPT that identifies security-related information in customer feedback, such an analysis could reveal that the probability of receiving a critical message depends on the hospital, the product, the time (e.g., shortly after service) or the language or length of the feedback.
Depending on this, the manufacturer would receive information about the safety of its product (e.g., timing) or the performance of its GPT (e.g., language or length of feedback).
5.3.5 Ensuring document control
The control of the GPT is a prerequisite for its standard-compliant validation. This control requires:
- The manufacturer has described what the GPT is and its intended purpose (see also 5.3.1).
- These elements of the GPT (prompts, RAG documents, model, model parameters, etc.) are under version control or at least documented per version.
- Changes to these elements are documented, reviewed, and approved.
The validation documentation is also subject to document control. This ranges from the system requirements to the evaluation/classification of the system and the test plans to the test results and test reports.
Configuration Management Databases (CMDB) are useful for inventorying systems and their validation statuses.
6. FAQ
This chapter is a work in progress. The Johner Institute will add further questions and answers as required.
6.1 How do you deal with the fact that systems are not deterministic?
As explained above, the goal is to achieve state-of-the-art technology. Neither a single person nor a group of people would be expected to achieve:
- Unrestricted reproducibility
- Absolute completeness
- One hundred percent correctness
Manufacturers should determine the degree of human reproducibility, completeness, and correctness and achieve it via their GPT, at least if humans represent the state of the art. Otherwise, manufacturers would increase the risks, which is not permitted according to ISO 14971, MDR, and IVDR.
If machines (e.g., “classic software”) represent the state of the art and operate in a fully reproducible and completely correct manner, non-deterministic results would be unacceptable.
However, these statements are only relevant if the GPT is subject to validation.
Model parameters can be used to make a GPT sufficiently deterministic. However, this is in all cases neither fundamentally required nor sensible.
6.2 Where should I start?
Start by making an inventory of your GPTs, for example using the following attributes:
- Name, ID of the system
- Intended purpose
- Process(es) in which it is used
- Validation requirement
- Risks
- State of the art (next best alternative)
Then check your SOP for CSV to see if it is also suitable for LLM-based systems. Adjust it if necessary.
Then create the first validation plan for the GPT with the highest risk.
If you get stuck on any of the steps or want to delegate these tasks, please contact us.
7. Conclusion and summary
GPTs such as ChatGPT help medical device manufacturers work more efficiently and productively, thereby improving their competitiveness. That is why they should take advantage of these new technical possibilities.
However, they must not operate in a legal vacuum. Statements such as “GPTs cannot be validated anyway, so I don’t have to do it” are both incorrect and misleading.
GPTs can be validated, even if the validation process has some special features. Apart from that, the best practices of the Computerized Systems Validation apply.
Manufacturers, authorities, and notified bodies should leave the validation church in the village and not demand anything that would not be demanded of humans or conventional systems. There is a state of the art.
You will need to validate your ChatGPT in many use cases. You can assume that your authority or notified body will address this in the next audit.
The Johner Institute supports manufacturers of medical devices and IVDs in
- decide on the validation requirements for GPTs,
- create specification documents such as SOPs, work instructions, and templates,
- validate GPTs in accordance with standards and regulations,
- select the appropriate methods, metrics, and tools for this purpose, improve the GPTs, and
- minimizing the effort required for all of this.
Get in touch, regardless of whether you just want suggestions or want to hand over the topic completely.